Linux Tutorials & Guides
Comprehensive, hands-on guides for Linux engineers. From fundamentals to advanced production patterns.

Install NVIDIA Drivers and CUDA on Linux Server for AI: The No-Nonsense Guide (2026)
Complete guide to installing NVIDIA drivers and CUDA on Ubuntu 24.04, RHEL 9, and Fedora 41 for AI workloads. Covers...

Docker Model Runner on Linux: Deploy and Serve AI Models with GPU Acceleration
Use Docker Model Runner on Linux to deploy, serve, and manage AI models with GPU acceleration, including setup, model...

5 Best AI Coding Assistants for the Linux Terminal: Hands-On Comparison
Hands-on comparison of 5 AI coding assistants for the Linux terminal: Claude Code, Aider, Continue, Open Interpreter,...
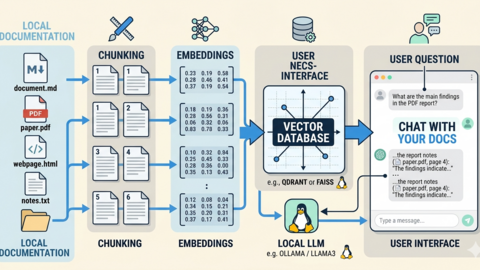
Build a Self-Hosted RAG Pipeline on Linux: Chat with Your Documentation
Build a private RAG pipeline on Linux using Ollama, ChromaDB, and Python to chat with your own documentation, wikis,...
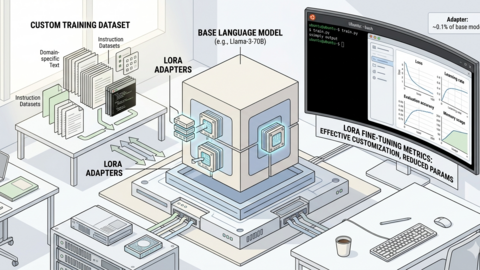
LoRA Fine-Tuning on Linux: Customize LLMs with Your Own Data
Fine-tune LLMs with LoRA and QLoRA on Linux. Covers data preparation, training configuration, GPU requirements,...
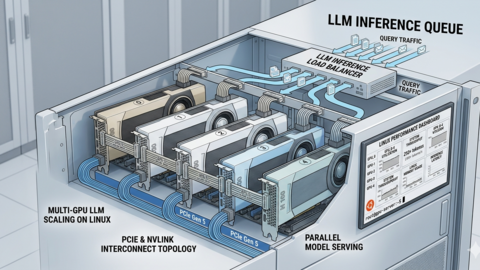
Multi-GPU LLM Inference on Linux: Setup, Load Balancing, and Scaling
Configure multi-GPU LLM inference on Linux with Ollama and vLLM, including tensor parallelism, load balancing across...
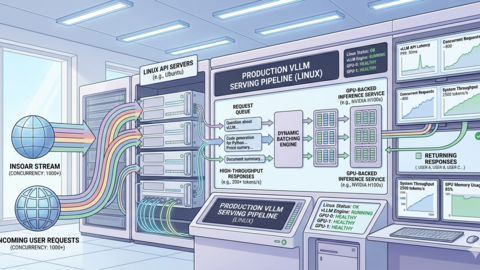
vLLM on Linux: Production Deployment Guide for High-Throughput Inference
Deploy vLLM on Linux for production LLM inference. Covers installation, API server config, tensor parallelism,...

Power Consumption: Running LLMs 24/7 on Linux — Real Electricity Costs
Real-world power measurements and electricity costs for running LLMs on Linux 24/7. Covers GPU monitoring, cost...
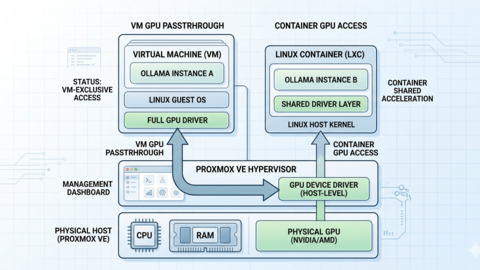
Ollama on Proxmox: GPU Passthrough for LXC and VM AI Workloads
Configure NVIDIA GPU passthrough on Proxmox for Ollama AI workloads in both LXC containers and VMs, with IOMMU setup,...
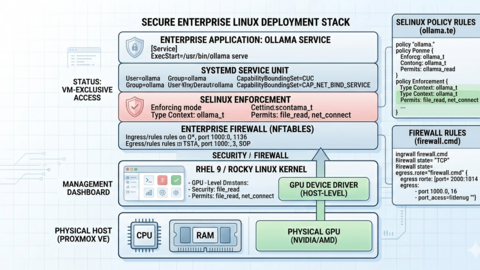
Ollama on RHEL 9 and Rocky Linux: Enterprise Setup and SELinux Guide
Deploy Ollama on RHEL 9 and Rocky Linux with proper SELinux policies, firewalld rules, NVIDIA drivers, Podman support,...
Self-Hosted AI Email Assistant on Linux with n8n and Ollama
Build a self-hosted AI email assistant on Linux using n8n and Ollama. Covers email classification, auto-drafting...
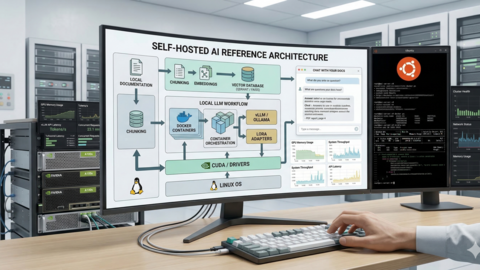
Self-Hosted AI Stack for Linux Sysadmins: Complete Reference Architecture
Design and deploy a production self-hosted AI stack on Linux with Ollama, Open WebUI, vector databases, and reverse...