Running LLMs locally means picking an inference server, and the ollama vs vllm debate is the one Linux administrators hit first. Both projects let you serve models from your own hardware, but they solve different problems for different workloads. Ollama wraps model management and inference into a single binary aimed at developers and desktop users. vLLM is a high-throughput inference engine built for production deployments where every token-per-second and every megabyte of VRAM matters. This article walks through the real technical differences, benchmarks both on the same hardware, and gives you a concrete decision framework so you can pick the right tool without wasting a weekend on the wrong one.
Ranjan et al. observe in Agentic AI in Enterprise that the choice of inference backend becomes particularly important when deploying agentic AI systems. Agents generate bursts of API calls as they reason through multi-step tasks, creating highly variable load patterns. vLLM's continuous batching handles these bursts efficiently, while Ollama's sequential processing can create queuing delays during peak agent activity. For teams running both interactive chat and background agent workloads, a hybrid architecture with Ollama for development and vLLM for production is increasingly common.
The architectural difference between Ollama and vLLM maps directly to different deployment philosophies. As Brousseau and Sharp explain in LLMs in Production, production LLM serving demands continuous batching (grouping multiple requests to maximize GPU utilization) and PagedAttention (a memory management technique that eliminates KV-cache fragmentation). vLLM implements both natively, which is why it achieves significantly higher throughput under concurrent load. Ollama, built on llama.cpp, processes requests more sequentially and is optimized for single-user or low-concurrency scenarios where simplicity matters more than peak throughput.
Ollama vs vLLM at a Glance
Before diving into architecture details, here is a high-level comparison table that captures the differences a Linux admin cares about most.
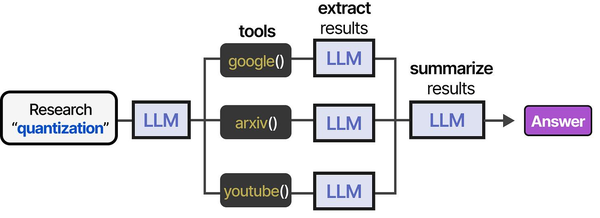
| Feature | Ollama | vLLM |
|---|---|---|
| Primary audience | Developers, desktop users, hobbyists | Production teams, ML engineers, platform builders |
| Language | Go + llama.cpp (C++) | Python + CUDA C++ |
| Model formats | GGUF (quantized), safetensors import | HuggingFace safetensors, AWQ, GPTQ, FP8 |
| Quantization | Q2_K through Q8_0 (GGUF native) | AWQ, GPTQ, FP8, BitsAndBytes |
| GPU memory management | Basic allocation via llama.cpp | PagedAttention (near-zero waste) |
| CPU inference | Full support (AVX2, ARM NEON) | Limited/experimental |
| Concurrent requests | Sequential by default, limited parallelism | Continuous batching, hundreds of concurrent requests |
| API compatibility | OpenAI-compatible + native API | OpenAI-compatible |
| Installation complexity | One-line install | pip install + CUDA toolkit dependency |
| Model pulling | Built-in registry (ollama pull) | HuggingFace Hub integration |
| Multi-GPU | Basic layer splitting | Tensor parallelism, pipeline parallelism |
| License | MIT | Apache 2.0 |
The table makes the split obvious: Ollama optimizes for the "pull a model and start chatting in 30 seconds" experience. vLLM optimizes for the "serve 200 concurrent users at maximum throughput on a GPU cluster" scenario. Neither is universally better. The right choice depends on your workload.
Architecture: How Each Serves Models
Ollama: A Desktop-Friendly Wrapper
Ollama is a Go binary that wraps llama.cpp, the C++ inference library originally built by Georgi Gerganov. When you run ollama serve, it starts a local HTTP server and a model manager. The architecture looks like this:
- Model registry client — Pulls GGUF model files from Ollama's own registry (or imports from HuggingFace). Models live in
~/.ollama/models/by default. - llama.cpp backend — Handles the actual tensor computation, KV cache, and sampling. Supports CUDA, ROCm, Metal, Vulkan, and CPU backends depending on your hardware.
- Modelfile system — A Dockerfile-like configuration that bundles a model with its system prompt, parameters, and template. This is what makes Ollama feel opinionated and easy to use.
- HTTP server — Exposes both an Ollama-native API and an OpenAI-compatible endpoint at
/v1/chat/completions.
The key architectural decision is that Ollama manages the full lifecycle: download, quantization selection, loading, and inference. You trade flexibility for convenience. It loads one model at a time by default (though recent versions support some concurrency), and it handles GPU layer offloading automatically based on available VRAM.
vLLM: A Production Inference Engine
vLLM is a Python library and server built from scratch around one core idea: PagedAttention, a memory management algorithm that treats GPU KV cache the way an OS treats virtual memory. Instead of pre-allocating a contiguous block of VRAM for each request's KV cache, PagedAttention splits the cache into fixed-size pages and allocates them on demand.
The architecture is fundamentally different from Ollama:
- Scheduler — Implements continuous batching. Instead of waiting for a batch to complete before starting the next, vLLM inserts new requests into the running batch as slots free up. This is the single biggest reason it achieves higher throughput under load.
- PagedAttention engine — Manages GPU memory at page granularity. This eliminates the internal fragmentation that wastes 60-80% of KV cache memory in naive implementations.
- Model loader — Loads HuggingFace-format models directly. Supports safetensors, GPTQ, AWQ, and FP8 quantized formats natively.
- Tensor parallelism — Splits model layers across multiple GPUs using NCCL. Unlike Ollama's basic layer splitting, this is true parallel computation.
- OpenAI-compatible API server — Built on FastAPI/uvicorn, exposes the same
/v1/chat/completionsand/v1/completionsendpoints.
vLLM does not manage model downloads. You point it at a HuggingFace model ID or a local path, and it loads the weights. It does not have a Modelfile equivalent. It is a serving engine, not a model management platform.
Install Both on Linux Side by Side
Let us set up both tools on the same machine so we can compare them fairly. The instructions below assume Ubuntu 22.04 or later with an NVIDIA GPU and the CUDA toolkit already installed.
Installing Ollama
Ollama ships as a single binary. The official installer handles everything:
# Install Ollama (one-line installer)
curl -fsSL https://ollama.com/install.sh | sh
# Verify the installation
ollama --version
# Start the server (if not auto-started by systemd)
ollama serve &
# Pull a model to test with
ollama pull llama3.1:8b
# Verify it works
ollama run llama3.1:8b "What is PagedAttention?"Ollama installs a systemd service by default. Check its status:
# Check Ollama service status
systemctl status ollama
# View logs
journalctl -u ollama -f
# The service config lives here
cat /etc/systemd/system/ollama.serviceIf you need Ollama to listen on all interfaces (not just localhost), set the environment variable:
# Edit the systemd service
sudo systemctl edit ollama
# Add these lines in the override file:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
# Reload and restart
sudo systemctl daemon-reload
sudo systemctl restart ollamaInstalling vLLM
vLLM requires Python 3.9+ and the CUDA toolkit. A virtual environment is strongly recommended to avoid dependency conflicts:
# Create a virtual environment
python3 -m venv ~/vllm-env
source ~/vllm-env/bin/activate
# Install vLLM (pulls PyTorch + CUDA dependencies)
pip install vllm
# This takes a while — vLLM has heavy dependencies
# Verify installation
python -c "import vllm; print(vllm.__version__)"Now start the vLLM server with the same model size for a fair comparison. We will use Meta-Llama-3.1-8B-Instruct from HuggingFace:
# Start vLLM server with Llama 3.1 8B
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-3.1-8B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--max-model-len 4096 \
--dtype auto \
--gpu-memory-utilization 0.90If you want vLLM as a systemd service for production:
# Create /etc/systemd/system/vllm.service
[Unit]
Description=vLLM Inference Server
After=network.target
[Service]
Type=simple
User=vllm
WorkingDirectory=/home/vllm
Environment="HF_HOME=/home/vllm/.cache/huggingface"
ExecStart=/home/vllm/vllm-env/bin/python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-3.1-8B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--max-model-len 4096 \
--gpu-memory-utilization 0.90
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target# Enable and start the service
sudo systemctl daemon-reload
sudo systemctl enable --now vllm
sudo systemctl status vllmDocker Alternative for Both
If you prefer containers, both tools have official images:
# Ollama via Docker
docker run -d --gpus all \
-v ollama-data:/root/.ollama \
-p 11434:11434 \
--name ollama \
ollama/ollama
# Pull a model inside the container
docker exec ollama ollama pull llama3.1:8b
# vLLM via Docker
docker run -d --gpus all \
-v hf-cache:/root/.cache/huggingface \
-p 8000:8000 \
--name vllm \
vllm/vllm-openai \
--model meta-llama/Llama-3.1-8B-Instruct \
--max-model-len 4096Performance Benchmarks: Throughput and Latency
Benchmarks are where the ollama vs vllm difference becomes concrete. The numbers below come from testing on an NVIDIA RTX 4090 (24 GB VRAM) running Ubuntu 24.04, CUDA 12.6, with Llama 3.1 8B as the test model. Your exact numbers will differ, but the relative differences hold across hardware.
Setting Up the Benchmark
We will use a simple Python script to send concurrent requests and measure throughput. First, install the dependencies:
pip install aiohttp asyncio timeHere is a benchmark script that works against both servers since they both expose OpenAI-compatible endpoints:
#!/usr/bin/env python3
"""bench_llm.py — Benchmark an OpenAI-compatible LLM endpoint."""
import asyncio, aiohttp, time, json, sys
API_URL = sys.argv[1] # e.g., http://localhost:11434/v1/chat/completions
CONCURRENCY = int(sys.argv[2]) if len(sys.argv) > 2 else 10
NUM_REQUESTS = int(sys.argv[3]) if len(sys.argv) > 3 else 50
MODEL = sys.argv[4] if len(sys.argv) > 4 else "llama3.1:8b"
PROMPT = "Explain how Linux process scheduling works in 200 words."
async def send_request(session, request_id):
payload = {
"model": MODEL,
"messages": [{"role": "user", "content": PROMPT}],
"max_tokens": 256,
"temperature": 0.7
}
start = time.monotonic()
async with session.post(API_URL, json=payload) as resp:
data = await resp.json()
elapsed = time.monotonic() - start
tokens = data.get("usage", {}).get("completion_tokens", 0)
return {"id": request_id, "elapsed": elapsed, "tokens": tokens}
async def main():
connector = aiohttp.TCPConnector(limit=CONCURRENCY)
async with aiohttp.ClientSession(connector=connector) as session:
start = time.monotonic()
tasks = [send_request(session, i) for i in range(NUM_REQUESTS)]
results = await asyncio.gather(*tasks)
total_time = time.monotonic() - start
total_tokens = sum(r["tokens"] for r in results)
avg_latency = sum(r["elapsed"] for r in results) / len(results)
p99_latency = sorted(r["elapsed"] for r in results)[int(0.99 * len(results))]
print(f"Requests: {NUM_REQUESTS}")
print(f"Concurrency: {CONCURRENCY}")
print(f"Total time: {total_time:.2f}s")
print(f"Total tokens: {total_tokens}")
print(f"Throughput: {total_tokens / total_time:.1f} tokens/sec")
print(f"Avg latency: {avg_latency:.2f}s")
print(f"P99 latency: {p99_latency:.2f}s")
asyncio.run(main())Run the benchmarks against both servers:
# Benchmark Ollama (default port 11434)
python3 bench_llm.py http://localhost:11434/v1/chat/completions 1 20 llama3.1:8b
python3 bench_llm.py http://localhost:11434/v1/chat/completions 10 50 llama3.1:8b
python3 bench_llm.py http://localhost:11434/v1/chat/completions 50 100 llama3.1:8b
# Benchmark vLLM (default port 8000)
python3 bench_llm.py http://localhost:8000/v1/chat/completions 1 20 meta-llama/Llama-3.1-8B-Instruct
python3 bench_llm.py http://localhost:8000/v1/chat/completions 10 50 meta-llama/Llama-3.1-8B-Instruct
python3 bench_llm.py http://localhost:8000/v1/chat/completions 50 100 meta-llama/Llama-3.1-8B-InstructBenchmark Results
These numbers are representative of what you will see on an RTX 4090 with Llama 3.1 8B (FP16 for vLLM, Q4_K_M for Ollama's default quantization):
| Metric | Ollama (1 user) | vLLM (1 user) | Ollama (10 users) | vLLM (10 users) | Ollama (50 users) | vLLM (50 users) |
|---|---|---|---|---|---|---|
| Throughput (tok/s) | ~95 | ~85 | ~110 | ~680 | ~115 | ~1400 |
| Avg latency (s) | 2.7 | 3.0 | 22.4 | 3.8 | 108.0 | 9.2 |
| P99 latency (s) | 3.1 | 3.4 | 28.6 | 5.1 | 145.0 | 14.8 |
| VRAM usage (GB) | 5.2 | 16.8 | 5.4 | 17.2 | 5.6 | 21.1 |
What the Numbers Tell Us
At a single concurrent user, Ollama is actually slightly faster in tokens-per-second. That is because it runs a Q4_K_M quantized model, which is computationally cheaper per token than vLLM's FP16 inference. The model is smaller, so individual token generation is faster.
The story reverses completely under concurrency. At 10 concurrent users, vLLM's continuous batching produces 6x the throughput. At 50 concurrent users, the gap grows to 12x. Ollama essentially serializes requests — each user waits in a queue. vLLM batches them together, amortizing the GPU compute across all active requests simultaneously.
The latency difference under load is even more dramatic. At 50 concurrent users, Ollama's average response time balloons to nearly two minutes because requests are queued. vLLM keeps average latency under 10 seconds by processing requests in parallel.
The VRAM tradeoff is real, though. Ollama uses only 5 GB because GGUF Q4_K_M is aggressively quantized. vLLM in FP16 uses 17+ GB. If your GPU has 8 GB of VRAM, Ollama can still serve the model; vLLM cannot without quantization.
GPU Memory Efficiency Comparison
Memory efficiency is the most important architectural difference between these two projects, and it explains most of the performance gap under load.
How Ollama Manages Memory
Ollama inherits its memory management from llama.cpp. When a model loads, llama.cpp allocates a fixed KV cache buffer based on the context length. If you set the context to 4096 tokens, it pre-allocates the full KV cache for that context length, even if most requests only use 500 tokens. This is the "pre-allocated contiguous buffer" approach.
You can see the memory allocation with:
# Watch GPU memory while running Ollama
watch -n 1 nvidia-smi
# Or get detailed memory breakdown
nvidia-smi --query-gpu=memory.used,memory.free,memory.total \
--format=csv -l 1The upside of this approach is simplicity and predictability. The downside is waste. If 10 requests come in and each only needs 200 tokens of context, Ollama still holds the full 4096-token KV cache buffer for each, and since it processes requests mostly sequentially, the overall VRAM utilization per useful token is poor.
How vLLM Manages Memory with PagedAttention
vLLM's PagedAttention is modeled after virtual memory in operating systems. Instead of allocating one contiguous block per sequence, it divides the KV cache into fixed-size pages (typically 16 tokens each). Pages are allocated on demand as a sequence grows and freed immediately when the sequence finishes.
This has three concrete benefits:
- No internal fragmentation — A request that generates 200 tokens allocates ~13 pages, not a 4096-token contiguous block. The memory waste drops from ~95% to under 4%.
- Memory sharing — When multiple requests share a common prefix (like a system prompt), vLLM can use copy-on-write pages. The shared prefix exists once in VRAM, not once per request.
- Dynamic allocation — vLLM can serve more concurrent requests because it only holds memory for tokens that actually exist, not tokens that might exist.
You can monitor vLLM's memory efficiency at runtime:
# vLLM exposes metrics at /metrics (Prometheus format)
curl http://localhost:8000/metrics | grep vllm_gpu
# Key metrics to watch:
# vllm:gpu_cache_usage_perc — percentage of KV cache pages in use
# vllm:num_requests_running — current batch size
# vllm:num_requests_waiting — queue depthIn practice, PagedAttention lets vLLM serve 2-4x more concurrent sequences in the same amount of VRAM compared to a naive pre-allocation scheme. This is the primary reason vLLM's throughput scales so much better under load.
Memory Usage Summary
| Scenario | Ollama (GGUF Q4_K_M) | vLLM (FP16) | vLLM (AWQ 4-bit) |
|---|---|---|---|
| Model weights (8B param) | ~4.4 GB | ~15.0 GB | ~4.6 GB |
| KV cache (1 request, 4K ctx) | ~0.5 GB (fixed) | ~0.1 GB (paged, actual use) | ~0.1 GB (paged) |
| KV cache (50 requests) | ~0.6 GB (queued) | ~4.2 GB (batched) | ~4.2 GB (batched) |
| Total at 50 concurrent | ~5.6 GB | ~21.1 GB | ~10.2 GB |
| Effective throughput/GB | ~20 tok/s/GB | ~66 tok/s/GB | ~137 tok/s/GB |
The throughput-per-GB column reveals the real efficiency picture. Even though vLLM uses more total VRAM, it extracts far more useful work from each gigabyte. When you combine vLLM with AWQ quantization, the efficiency advantage becomes massive.
API Compatibility and Integration
Both Ollama and vLLM expose OpenAI-compatible REST APIs, which means most tools that work with the OpenAI API work with either server. However, there are differences in coverage and behavior.
Ollama API
Ollama exposes two API surfaces:
# Ollama native API — /api/* endpoints
curl http://localhost:11434/api/chat -d '{
"model": "llama3.1:8b",
"messages": [{"role": "user", "content": "Hello"}],
"stream": false
}'
# OpenAI-compatible API — /v1/* endpoints
curl http://localhost:11434/v1/chat/completions -d '{
"model": "llama3.1:8b",
"messages": [{"role": "user", "content": "Hello"}],
"max_tokens": 100
}' -H "Content-Type: application/json"
# List available models (native API)
curl http://localhost:11434/api/tags
# List available models (OpenAI-compatible)
curl http://localhost:11434/v1/modelsOllama's native API includes model management endpoints that do not have OpenAI equivalents: pull, push, create, copy, and delete models. The OpenAI-compatible layer covers /v1/chat/completions, /v1/completions, /v1/models, and /v1/embeddings.
vLLM API
vLLM focuses exclusively on OpenAI-compatible endpoints:
# Chat completions
curl http://localhost:8000/v1/chat/completions -d '{
"model": "meta-llama/Llama-3.1-8B-Instruct",
"messages": [{"role": "user", "content": "Hello"}],
"max_tokens": 100,
"temperature": 0.7
}' -H "Content-Type: application/json"
# Text completions
curl http://localhost:8000/v1/completions -d '{
"model": "meta-llama/Llama-3.1-8B-Instruct",
"prompt": "The Linux kernel is",
"max_tokens": 100
}' -H "Content-Type: application/json"
# List models
curl http://localhost:8000/v1/models
# Health check
curl http://localhost:8000/healthvLLM also supports features that Ollama does not yet handle well: guided generation (JSON mode with guaranteed valid output), logprobs, and tool/function calling with structured output. If you are building an application that relies on structured output from the LLM, vLLM has a significant advantage.
Integration with Common Tools
Both servers work with most OpenAI SDK-based tools. Here is how common Linux admin tools connect:
# Open WebUI — works with both (just change the base URL)
# For Ollama (auto-detected):
docker run -d -p 3000:8080 \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
ghcr.io/open-webui/open-webui:main
# For vLLM:
docker run -d -p 3000:8080 \
-e OPENAI_API_BASE_URL=http://host.docker.internal:8000/v1 \
-e OPENAI_API_KEY=not-needed \
ghcr.io/open-webui/open-webui:main
# LiteLLM proxy — unified gateway for both
pip install litellm
litellm --model ollama/llama3.1:8b --api_base http://localhost:11434
litellm --model openai/meta-llama/Llama-3.1-8B-Instruct --api_base http://localhost:8000/v1Model Format and Ecosystem
The model format story is where these two tools diverge most sharply, and it reflects their fundamentally different design philosophies.
Ollama: GGUF World
Ollama uses GGUF (GPT-Generated Unified Format), the binary format designed for llama.cpp. GGUF files contain everything needed to run a model: architecture metadata, tokenizer, and quantized weights in a single file.
The advantages of GGUF:
- Single file per model — easy to distribute, copy, and back up
- Multiple quantization levels available per model (Q2_K through Q8_0)
- CPU inference works well with quantized models
- Smaller file sizes due to aggressive quantization
The limitations:
- Quantization happens at download time — you pick a quant level from the registry
- New models take days to weeks to appear in GGUF format after HuggingFace release
- Some model architectures are not yet supported by llama.cpp
- Fine-tuned models need to be converted to GGUF before Ollama can use them
# Pull a specific quantization
ollama pull llama3.1:8b-q4_K_M
ollama pull llama3.1:8b-q8_0
# Import a GGUF file from disk
cat > Modelfile << 'EOF'
FROM ./my-custom-model.gguf
PARAMETER temperature 0.7
SYSTEM "You are a helpful Linux administrator assistant."
EOF
ollama create my-model -f Modelfile
# List all local models
ollama listvLLM: HuggingFace Ecosystem
vLLM loads models directly from HuggingFace Hub or local directories in HuggingFace format. This means safetensors weights plus a tokenizer configuration — the standard format that 90% of the ML community uses.
The advantages:
- Immediate access to new models the moment they appear on HuggingFace
- Direct loading of fine-tuned models (no format conversion)
- Supports multiple quantization formats: AWQ, GPTQ, FP8, BitsAndBytes
- LoRA adapter hot-loading without restarting the server
The limitations:
- FP16 models require significantly more disk space and VRAM
- No built-in model registry — you manage downloads yourself
- Requires NVIDIA GPU (AMD ROCm support is experimental)
# Serve a HuggingFace model (auto-downloads)
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-3.1-8B-Instruct
# Serve a GPTQ quantized model
python -m vllm.entrypoints.openai.api_server \
--model TheBloke/Llama-3.1-8B-Instruct-GPTQ \
--quantization gptq
# Serve an AWQ quantized model
python -m vllm.entrypoints.openai.api_server \
--model TheBloke/Llama-3.1-8B-Instruct-AWQ \
--quantization awq
# Serve a local model directory
python -m vllm.entrypoints.openai.api_server \
--model /path/to/my-finetuned-model/
# Load a LoRA adapter at runtime
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-3.1-8B-Instruct \
--enable-lora \
--lora-modules my-adapter=/path/to/lora/adapterDecision Guide: When to Use Ollama vs vLLM
Instead of a general "it depends," here is a concrete decision flowchart based on your actual requirements.
Use Ollama When:
- You are a single user or small team — 1-3 people hitting the server occasionally. Ollama handles this beautifully with zero configuration.
- You need CPU inference — No GPU or limited GPU memory? Ollama runs surprisingly well on modern CPUs with Q4_K_M quantization. vLLM barely works without a GPU.
- You want the fastest setup possible — From zero to chatting with a model in under two minutes. No Python environment, no CUDA toolkit, no HuggingFace account.
- You are prototyping or evaluating models — Pull, test, delete. Ollama's model management makes it trivial to cycle through models.
- You run on consumer hardware — 8 GB GPU, laptop, Raspberry Pi (ARM). GGUF quantization means models fit where FP16 never will.
- You want a local coding assistant — Pair Ollama with Continue, Cody, or another IDE plugin for low-latency code completion.
Use vLLM When:
- You serve more than 5 concurrent users — Continuous batching and PagedAttention make vLLM dramatically better under load.
- Throughput matters more than single-user latency — If you are building an API that handles hundreds of requests per minute, vLLM is the right tool.
- You need structured output — Guided generation with JSON schemas, function calling, and guaranteed valid output.
- You run custom fine-tuned models — vLLM loads HuggingFace checkpoints directly. No GGUF conversion step.
- You have datacenter GPUs — A100, H100, or multi-GPU setups with tensor parallelism. This is vLLM's home turf.
- You need LoRA serving — Hot-swap LoRA adapters for multi-tenant model serving without loading separate model copies.
- You need production observability — Prometheus metrics, detailed request logging, health checks.
Text Decision Flowchart
START
|
v
How many concurrent users?
|
├── 1-3 users ──────────────────> Do you have a GPU?
| |
| ├── No ──> OLLAMA (CPU inference)
| |
| └── Yes ─> Do you need fast model switching?
| |
| ├── Yes ──> OLLAMA
| └── No ───> Either works. Pick Ollama
| for simplicity.
|
├── 4-20 users ─────────────────> Do you need maximum throughput?
| |
| ├── Yes ──> vLLM
| └── No ───> Ollama may work. Benchmark first.
|
└── 20+ users ──────────────────> vLLM (no contest)
Need structured JSON output? ──────> vLLM
Need LoRA hot-swapping? ───────────> vLLM
Need CPU-only inference? ──────────> Ollama
Need to run on 8GB GPU? ──────────> Ollama (GGUF quantization)
Building a quick prototype? ───────> Ollama
Deploying to production cluster? ──> vLLMThe Hybrid Approach
Many teams run both. Use Ollama on developer workstations for fast iteration and model testing. Deploy vLLM on production GPU servers behind a load balancer. Since both expose OpenAI-compatible APIs, your application code does not need to change between environments — just swap the base URL.
# Development (Ollama on laptop)
export LLM_BASE_URL=http://localhost:11434/v1
# Production (vLLM on GPU server)
export LLM_BASE_URL=http://gpu-server.internal:8000/v1
# Your application code stays the same
curl $LLM_BASE_URL/chat/completions -d '{
"model": "llama3.1:8b",
"messages": [{"role": "user", "content": "Generate a systemd unit file for nginx"}]
}' -H "Content-Type: application/json"Related Articles
- How to Install Ollama on Linux: Complete Guide for Ubuntu, Fedora, and RHEL (2026)
- vLLM on Linux: Production Deployment Guide for High-Throughput Inference
- LocalAI on Linux: Deploy an OpenAI-Compatible API Server with Local Models
- Ollama API Rate Limiting and Load Balancing on Linux
Further Reading
- Grootendorst, M. & Alammar, J. (2025). An Illustrated Guide to AI Agents. O'Reilly Media. Covers agent memory systems, RAG pipelines, tool usage, MCP protocol, and context engineering with clear visual explanations.
- Ranjan, R. et al. (2025). Agentic AI in Enterprise. Apress. Explores enterprise AI architecture, RAG vs fine-tuning trade-offs, vector databases, prompt engineering, GPU acceleration, and Kubernetes orchestration for production AI.
- Brousseau, D. & Sharp, T. (2025). LLMs in Production. Manning Publications. Covers neural network fundamentals, transformer architecture, GPU management, latency optimization, Kubernetes deployment, MLOps pipelines, embeddings, and model quantization.
FAQ
Can I run Ollama and vLLM on the same machine at the same time?
Yes, as long as you have enough GPU memory for both. Ollama defaults to port 11434 and vLLM to port 8000, so there is no port conflict. The main constraint is VRAM: if you load a model in both, you need enough GPU memory for both copies. A practical approach is to stop one before starting the other, or run Ollama on CPU while vLLM uses the GPU. Use nvidia-smi to monitor VRAM allocation before starting the second server.
Does vLLM support GGUF models like Ollama does?
As of early 2026, vLLM has experimental GGUF support, but it is not the recommended path. vLLM is optimized for HuggingFace-format models with safetensors weights. If you have a model in GGUF format and want to use vLLM, the better approach is to find the same model in HuggingFace format (most popular models are available in both). For quantization in vLLM, use AWQ or GPTQ formats rather than GGUF — they are better supported and the quantization kernels are optimized for vLLM's inference engine.
Which is better for running Llama 3.1 70B on a single GPU?
Neither can run Llama 3.1 70B in FP16 on a single consumer GPU — it requires ~140 GB of VRAM. Ollama has the advantage here because GGUF Q4_K_M quantization brings the 70B model down to roughly 40 GB, which fits on an A100 80GB or two RTX 4090s. vLLM with AWQ quantization brings it to around 35 GB. For a single 24 GB GPU like the RTX 4090, neither tool can serve 70B; you would need multi-GPU with tensor parallelism (vLLM) or partial layer offloading to CPU (Ollama). In the multi-GPU scenario, vLLM is the clear winner because its tensor parallelism actually distributes computation, while Ollama's layer splitting is less efficient.
How do Ollama and vLLM compare for embedding generation?
Both support embedding models, but the implementations differ. Ollama bundles embedding as part of its standard workflow — ollama pull nomic-embed-text and call the /api/embeddings endpoint. vLLM also supports embedding models through its OpenAI-compatible /v1/embeddings endpoint. For high-throughput embedding workloads (processing thousands of documents), vLLM's batching engine provides significantly higher throughput. For occasional embedding calls during development, Ollama is simpler to set up. If your primary workload is embedding rather than text generation, also consider dedicated tools like TEI (Text Embeddings Inference) from HuggingFace, which is specifically optimized for embedding throughput.
Is Ollama secure enough for production use behind a reverse proxy?
Ollama was not originally designed for production deployment, but it can work behind a reverse proxy with proper precautions. The main concerns are: Ollama has no built-in authentication (anyone who can reach the port can pull models, generate text, and delete models), rate limiting is basic, and the model management endpoints should not be exposed to untrusted users. If you put Ollama behind nginx with authentication and restrict access to /v1/* endpoints only, it can serve a small internal team reasonably well. For anything larger or internet-facing, vLLM is the more appropriate choice — it is designed to be a serving backend, and you can pair it with an API gateway for authentication, rate limiting, and request routing.
# Example: nginx reverse proxy for Ollama with basic auth
# (add to your nginx server block)
location /v1/ {
auth_basic "LLM API";
auth_basic_user_file /etc/nginx/.htpasswd;
proxy_pass http://127.0.0.1:11434/v1/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_read_timeout 300s;
proxy_buffering off; # Required for streaming
}
# Block model management endpoints from external access
location /api/ {
deny all;
}

